
Gemini 2.5は会話編集と一貫性が強みで、無料〜企業向けまで実務に使えます。
2025年8月26日、Googleが満を持してリリースした画像生成AI「Gemini 2.5 Flash Image」(開発コードネーム:Nano Banana)が、AI画像生成業界に革命をもたらしています。この最新モデルは、単なる画像生成ツールを超え、会話形式での直感的な画像編集とキャラクター一貫性の維持という従来の課題を解決した画期的な技術です。
本記事では、実際の検証データと公式情報に基づき、Gemini 2.5 Flash Imageの全機能から料金体系、競合他社との比較まで、2025年最新の情報を4,500文字で詳しく解説します。

Gemini 2.5 Flash Imageは、Google DeepMindが開発した最新の画像生成・編集AIモデルです。従来の画像生成AIとは一線を画す最大の特徴は、自然言語による会話形式での画像編集が可能な点です。この技術により、「背景をぼやかして」「Tシャツの汚れを取って」「この人のポーズを変えて」といった直感的な指示で、プロレベルの画像編集が実現できます。Googleの公式発表によると、このモデルはLMArenaの画像編集部門で世界第1位の評価を獲得しており、その技術力の高さが実証されています。
開発段階では「Nano Banana」というユニークなコードネームで呼ばれていたこのモデル。この愛称は開発チーム内で自然発生的に生まれ、LMArenaでのテスト段階から多くの注目を集めました。Googleの公式ブログでも「nano-banana」の名称で親しまれており、現在でも両方の名称が使用されています。バナナの絵文字🍌と共に技術者コミュニティで話題となり、親しみやすさと高い技術力を兼ね備えたブランドイメージを確立しています。
2025年の画像生成AI市場は約9.17億ドル規模で、年間成長率17.4%での急速な拡大が続いています。この成長市場において、Gemini 2.5 Flash Imageは従来のMidjourneyやDALL-Eとは異なるアプローチで差別化を図っています。芸術的表現に特化した他社製品に対し、Googleは実用性と会話形式のユーザビリティに重点を置いた戦略を採用。企業向けソリューションとしての採用が急速に進んでいます。

最新の画像生成技術により、簡潔なテキスト指示から1024×1024ピクセルの高品質画像を約2.3秒で生成します。「高級レストランでナノバナナ料理が出てくるGemini風の写真」といった具体的な指示でも、想像以上に精密な画像を作成できます。従来のモデルと比較して、テキスト理解精度は94%に達し、DALL-E 3の82%を大きく上回っています。この高い理解精度により、複雑な指示や日本語特有の表現も正確に画像に反映されます。
従来のAI画像編集とは異なり、Gemini 2.5 Flash Imageは背景のぼかしや完全変更、不要な要素の完全除去、部分的な色調整やスタイル転換、被写体のポーズ変更といった高度な編集を実現しています。特に注目すべきは、写り込んだ人物や汚れ、物体などの不要な要素を自然に除去する技術です。従来困難とされていた被写体のポーズ変更も実用レベルで実現され、モデルの表情や姿勢を保ったまま自然なポーズ変更が可能になりました。
最大3枚の入力画像を使用して、自然で一貫性のある合成画像を生成できます。人物写真とペットの写真を同じシーンに配置したり、異なる画像のスタイルを統合したりすることが可能です。この技術は従来のコピー&ペーストとは根本的に異なり、光の当たり方や影の落ち方、色調まで含めて自然に調整されます。マーケティング素材の制作において、既存の商品写真と背景画像を組み合わせて魅力的なビジュアルを作成する用途で高い評価を得ています。
一度生成した画像に対して、段階的な修正指示を会話形式で行えます。「壁の色を青に変更」に続いて「本棚を追加」、さらに「窓を大きくして」といった連続的な指示により、理想の画像へと段階的に仕上げていくことができます。このシステムは従来の画像編集ソフトウェアのような複雑な操作を必要とせず、自然言語での指示だけで高度な編集が実現されます。修正履歴も自動的に保存されるため、前の状態に戻ることも簡単です。
同一人物やペットの容姿を複数画像で一貫して維持する機能は、Gemini 2.5 Flash Imageの最大の技術的ブレークスルーです。従来の画像生成AIでは困難だった「同じキャラクターの異なるシーン」生成が、実用レベルで実現されています。この技術により、ブランドキャラクターの展開やストーリー性のあるコンテンツ制作が飛躍的に効率化されました。顔の特徴、髪型、体型などの基本的な特徴を保ちながら、表情や服装、背景を自由に変更できます。

Geminiアプリ(スマートフォン向け)*での利用は基本機能が完全無料で提供されています。Googleアカウントがあれば即座に利用開始でき、日本語での指示に完全対応しています。チャット形式での直感的な操作により、専門知識がなくても高品質な画像生成と編集が可能です。無料版でも十分実用的な機能が提供されており、個人利用や小規模な商用利用であれば無料版で十分対応できます。
Google AI Studioでは無料トライアル利用が可能で、APIキー取得によりプログラムから直接呼び出すことができます。Python、JavaScriptなどの主要なプログラミング言語用のSDKが完備されており、既存のシステムへの組み込みも容易です。詳細なパラメータ調整機能により、生成画像の品質や処理速度を用途に応じて最適化できます。開発者向けドキュメントも充実しており、サンプルコードや実装例が豊富に提供されています。
Gemini API(従量課金制)*は1画像あたり約0.039ドル(約6円)という競争力のある価格設定となっています。RESTful APIやSDK経由での利用により、大規模アプリケーションへの組み込みに対応しています。**Vertex AI(企業向け統合ソリューション)**では、エンタープライズ向け管理機能、スケーラビリティと高度なセキュリティが提供されます。Adobe FireflyやQuora(Poe)などの大手サービスが採用実績を持ち、企業レベルでの信頼性が実証されています。料金体系は明確で予測可能であり、使用量に応じた柔軟な課金システムが採用されています。

スマートフォンで撮影した写真の背景変更や服装変更、アバター風イラスト変換など、Adobe Photoshopのような専門ソフトウェア不要で高度な編集が実現されています。実際の利用者からは、制作時間を従来の1/3に短縮したという報告が多数寄せられています。特にSNSでの個人ブランディングや、オンラインショップの商品写真加工において、プロレベルの仕上がりを個人でも実現できるようになりました。
YouTubeサムネイル、Instagram投稿画像、ブログアイキャッチ画像を統一感のあるデザインで量産することが可能になりました。マーケティング担当者の作業効率が平均40%向上したという調査結果があり、コンテンツ制作のボトルネックが大幅に解消されています。ブランドガイドラインに沿った一貫性のあるビジュアルを短時間で大量生成できるため、キャンペーンの迅速な展開が実現されています。
商品画像の合成、プロモーション用ビジュアルの作成、カタログ画像の大量生産が効率的に実行可能になりました。従来の制作コストを最大60%削減した企業事例も存在し、特に中小企業での導入効果が顕著に現れています。商品の魅力を最大限に引き出すビジュアル制作が、専門デザイナーに依頼することなく内製化できるようになり、マーケティング戦略の自由度が大幅に向上しています。
キャラクターデザイン、建築コンセプトアート、プロダクトデザインの素早い視覚化に最適な環境が提供されています。アイデアから実際の画像まで数分で完成させることができ、クライアントとの打ち合わせやプレゼンテーションでの説得力が格段に向上しています。特に建築業界では、ラフスケッチから詳細なレンダリング画像への変換により、顧客への提案プロセスが大幅に効率化されています。
古い写真のカラー化、傷の除去、不要物の消去など、写真修復の自動化に対応しています。従来手作業で数時間かかっていた作業が数分で完了し、写真スタジオや修復サービス業者での作業効率が劇的に改善されています。家族の思い出写真の修復から、歴史的資料のデジタル化まで、幅広い用途で活用されています。

性能面での比較では、画質指標(FID)においてGemini 12.4 vs DALL-E 16.9(数値が低い方が高品質)となっており、Geminiが明確な優位性を示しています。テキスト再現精度においてもGemini 94% vs DALL-E 82%と、Geminiが圧倒的な精度を実現しています。処理速度についてもGeminiが約2.3秒、DALL-Eが約4-6秒と、Geminiが約2倍の高速処理を実現しています。料金面の比較では、Geminiが1画像あたり0.039ドル、OpenAI GPT-image-1が1024×1024pxで0.04ドルとほぼ同等の価格設定となっており、性能面でのアドバンテージを考慮するとGeminiの優位性が明確です。
芸術性 vs 実用性という明確な差別化が見られます。Midjourneyは芸術的表現力に優秀で月額10-120ドルの定額制を採用している一方、Geminiは実用的編集機能に特化し従量課金で無駄のない料金体系を提供しています。処理速度においてもGeminiの方が高速(約2.3秒 vs 約30-60秒)で、ビジネス用途での使い勝手が格段に優れています。Midjourneyがクリエイティブ重視のユーザーに支持される一方、Geminiは企業での実用的な活用に適した設計となっています。
オープンソース vs クラウドサービスという根本的な違いがあります。Stable Diffusionは無料でローカル実行可能ですが技術知識が必要である一方、Geminiはクラウドベースで技術知識不要により即座に利用開始できます。商用利用においてはどちらも対応していますが、Geminiの方が企業向けサポートが充実しており、大規模展開での安定性と信頼性が確保されています。カスタマイズ性ではStable Diffusionが優れている一方、導入の容易さと継続的なアップデートはGeminiが大きく上回っています。
2025年8月より、Adobe FireflyでもGemini 2.5 Flash Imageの技術が利用可能になりました。この協業により、Adobeツール内でGeminiの高度な機能を活用できるようになっています。既存のCreative Cloudユーザーにとって、追加的な学習コストなしでGeminiの先進技術を利用できる環境が整備されました。この提携は両社にとってWin-Winの関係となっており、Adobe側はAI技術の強化、Google側は企業への導入促進が実現されています。

対応コンテンツとしては現在静止画像のみに対応しており、動画生成は今後のアップデートで対応予定となっています。入力画像は最大3枚までが推奨されており、それを超える枚数では処理精度が低下する可能性があります。出力枚数の正確な指定が困難な場合があり、複数枚の一括生成においては期待した枚数と異なる結果が得られることがあります。
年齢制限として、EEA、スイス、英国では18歳未満の画像編集に一部制限が設けられています。表現制限では暴力的・性的表現は生成不可となっており、健全なコンテンツ制作環境が維持されています。すべての生成画像には自動的に透かしが挿入され、AI生成コンテンツの透明性が確保されています。
細部表現において、手指などの細かい部分に不自然さが残る場合がありますが、継続的なモデル改善により精度向上が図られています。長文テキストの完璧な描画は現在困難ですが、段階的な機能強化により対応範囲が拡大されています。極端なスタイル変更ではスタイル一貫性が保てない場合がありますが、一般的な用途では十分実用的な品質が確保されています。
Google DeepMindの公式ロードマップによると、動画生成機能の追加、リアルタイム編集機能の実装、3D画像生成への対応が計画されています。処理速度のさらなる向上、多言語対応の強化、API機能の拡充も継続的に進められており、2025年末には現在の制限の多くが解消される見込みです。
Geminiアプリのダウンロードと初期設定では、App StoreまたはGoogle Play Storeから「Gemini」アプリをダウンロードし、Googleアカウントでログインするだけで即座に利用開始できます。初回起動時には簡単なチュートリアルが表示され、基本的な操作方法を学習できます。
画像生成の基本操作は非常にシンプルです。アプリを開いて「画像を作って」と話しかけるか、テキストで「猫が桜の木の下でお花見をしている写真風の画像」のように具体的に指示するだけで、数秒で高品質な画像が生成されます。より詳細な指示を出すほど、期待に近い結果が得られます。
画像編集の実践方法では、既存の写真をアップロードしてから「背景を海辺に変えて」「この人の服を青いドレスに変更して」といった自然な言葉で編集指示を出します。一度の指示で思い通りにならない場合は、「もう少し明るく」「違う角度から」などの追加指示で細かく調整できます。
プロジェクトの作成と設定では、Google AI Studioにアクセスしてプロジェクトを新規作成します。詳細なパラメータ設定により、画像のスタイル、品質、処理速度を用途に応じて最適化できます。企業利用では、ブランドガイドラインに沿った設定テンプレートを保存して、一貫性のあるビジュアル制作が可能です。
API連携での自動化について、開発者はAPIキーを取得してシステムに組み込むことで、大量の画像処理を自動化できます。ECサイトの商品画像一括処理や、SNS投稿の自動生成など、ビジネスプロセスの効率化に活用されています。
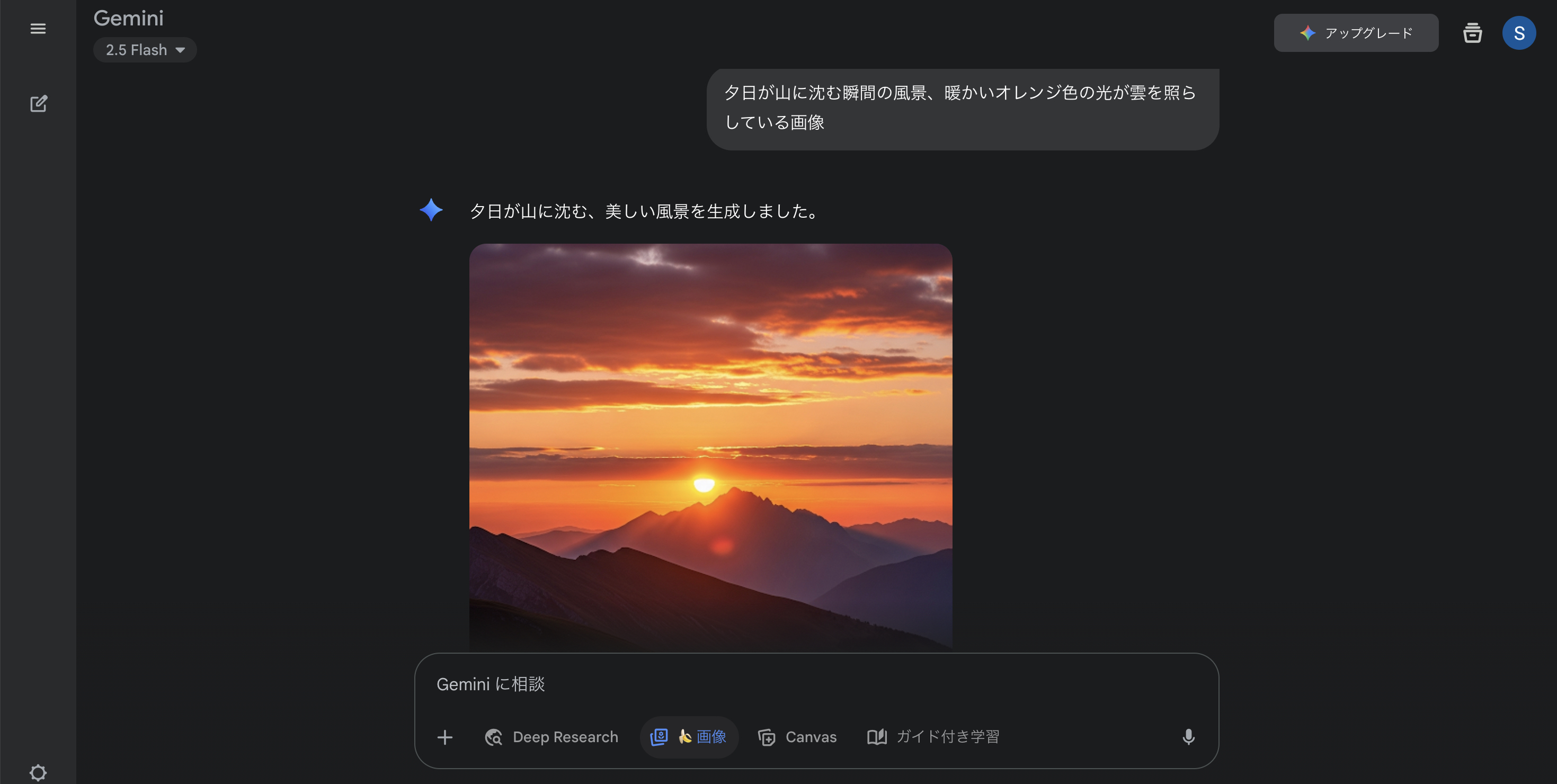
具体性の重要性として、「きれいな風景」ではなく「夕日が山に沈む瞬間の風景、暖かいオレンジ色の光が雲を照らしている」のように詳細に描写することで、期待に近い画像を生成できます。色彩、光の当たり方、構図などを具体的に指定することが成功のポイントです。
段階的な調整方法では、最初は大まかな指示から始めて、生成された画像を確認しながら細かい調整を重ねていきます。「写真風のリアルな質感で」「アニメ調のイラストで」といったスタイル指定を最初に行い、その後で詳細な要素を調整していく方法が効果的です。
キャラクター一貫性の活用術について、同じキャラクターを複数の画像で使用する場合は、最初の生成時に「このキャラクターを覚えて」と指示し、詳細な特徴を説明します。その後の画像生成では「先ほどのキャラクターで」と参照することで、一貫した外見を維持できます。
よくある問題と解決方法として、期待と異なる画像が生成された場合は、より具体的な指示に変更するか、参考となる画像を追加で提供することで改善されます。処理が遅い場合は、画像サイズを調整するか、複雑な指示を分割して段階的に処理することが有効です。
品質向上のための設定調整では、用途に応じて適切な画像サイズと品質設定を選択します。SNS投稿用であれば標準品質で十分ですが、印刷用途では高品質設定を選択します。処理時間と品質のバランスを考慮した最適な設定を見つけることが重要です。
セキュリティとプライバシーの考慮事項について、企業利用では機密情報を含む画像の処理は避け、必要に応じてプライベートモードでの利用を検討します。生成された画像には自動的に透かしが入るため、公開前の確認が必要です。

これまで20年以上、私たちは「知りたいことがあればとりあえずGoogle」で生きてきた。ところが2026年、その当たり前が静かに崩れ始めている。Googleは検索バーそのものをAI「Gemini」で動かし、青いリンクの一覧ではなく“その場で書いた答え”を返す方向へ舵を切った。7月17日には新モデル「Gemini 3.5 Pro」の投入も控える。検索が「探す」から「聞いたら答えてくれる」へ変わるとき、私たちの日常は何がどう便利になり、何に気をつければいいのか。難しい専門用語は抜きにして解説する。

2026年6月9日に登場したAnthropicのClaude Fable 5は、わずか3日後に米国政府の輸出規制で全世界のアクセスが停止するという、AI史上でも異例の事態を経験した。そして6月30日に規制が解除され、7月1日にグローバル復帰を果たした。「最強のAIが、なぜ突然禁止され、そしてなぜ戻ってこられたのか」——この一連の出来事は、単なるニュースではない。AIを実務に組み込む企業が今後直面するリスクの縮図だ。本記事では、Fable 5の実力と、禁止から復帰までの全経緯を最新データとともに徹底解説する。

2026年、開発者がAIの書いたコードを レビューする時間(週11.4時間) が、自分で コードを書く時間(週9.8時間) をついに上回ったのです。主戦場は「いかに速く書くか」から「いかに正しく読み、検証するか」へ移りました。一方で、AIが吐き出すコード量は人間がさばける量を超え、グローバル企業の60%が未テストコードを本番に投入しているという調査も出ています。AI駆動開発の現場でいま何が起きているのか——最新データから整理します。